컴퓨터가 사람을 이해하는 법은? 비트(Bit)이다.

데이터를 나타내는 최소의 단위를 비트(Bit)라고 하며.
컴퓨터가 받아들이는 모든 정보는 0 또는 1로 변환되어 메모리에 저장된다.
이 때, 메모리에 있는 이진수(Binary)의 한 자리를 '비트(Bit)' 라고 한다.
앞서 말했듯 컴퓨터의 정보를 비트로만 설정한다면, 0 또는 1의 정보만 구분할 수 있다.
그래서 훨씬 다양한 데이터를 표현하기 위해 여러 비트를 묶어 정보를 나타낼 수 있다.
예를 들어, 1Bit는 0과 1로 2가지를 나타내지만, 2Bit는 00,01,10,11 총 4가지(2의 2제곱)의 표현을 할 수 있으며,
3Bit는 2의 3제곱인 8가지의 표현을 할 수 있다.
즉, 비트의 수에 따라 2의 n제곱의 정보를 표현할 수 있다.
바이트(Byte)란?
'바이트(Byte)'는 8개의 비트를 나타낸 것으로, 말 그대로 1Byte에 2의 8제곱이다.
즉 256(0~255) 가지의 표현이 가능하다.

예를 들어, 150이라는 우리가 쓰는 10진수는 10010110 이라는 2진수로 나타낼 수 있고,
100은 01100100, 255는 11111111 로 나타낼 수 있다.
더 나아가 2Byte 혹은 4Byte를 이용해 값을 나타낼 수 있다.
2Byte는 2의 16제곱인 65,536개의 수를, 4Byte는 2의 32제곱의 수를 나타낼 수 있겠다.
이러한 바이트(Byte)를 사람의 언어를 컴퓨터 언어로 바꾸는 과정을 Encoding이라고 하며,
그 역을 Decoding이라고한다.
전달 할 때 ASCII 코드로 하고, 전달할 때는 DK 코드로 해석한다면 정보가 잘못 전달된다.
이러한 경우를 Decoing 오류라고 한다.
그렇다면, 숫자가 아닌 문자는 어떻게 바이트 배열로 표현할 수 있을까?
예시부터 보면, 알파벳 'A'는 0100001, 'N'은 01001110 으로 표현한다.
위의 예시는 문자를 표현하기 위해 사람들이 약속한 아스키(ASCII)코드이다.
ASCII는 각 문자를 7비트로 표현하므로 총 128개의 문자를 표현할 수 있다.
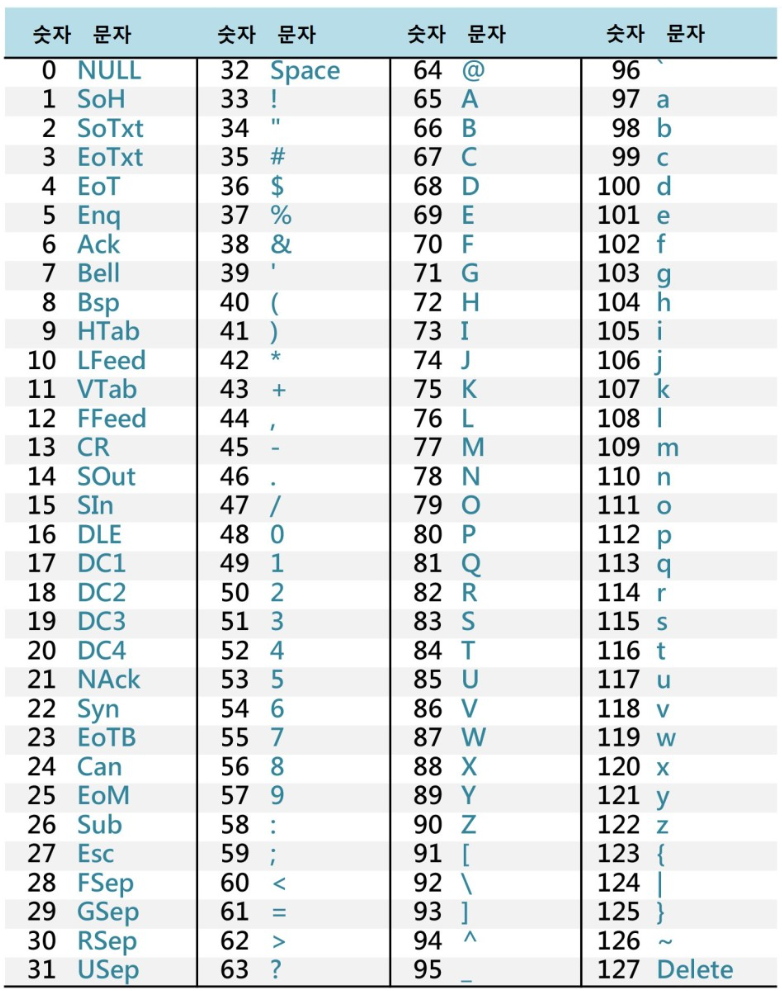
참고: https://terms.naver.com/entry.naver?docId=2270339&cid=51173&categoryId=51173
당연하게도 우리가 사용하는 한국어나, 지구상에 존재하는 많은 언어들을 담기에는
128개의 문자를 표현하는 ASCII 코드로는 턱도 없이 부족하다.
이렇게, 지구상에 존재하는 수많은 문자들과, 각종 특수문자 등을 표현하기 위해
2바이트, 또는 그 이상의 바이트를 이용하여 전체적인 문자열을 나타내는 것이
바로 유니코드(Unicode)이다.

유니코드는 사용중인 운영체제, 프로그램, 언어에 관계없이 문자마다 고유한 코드 값을 제공하는 새로운 개념의 코드이다.
참 : https://terms.naver.com/entry.naver?docId=2270340&cid=51173&categoryId=51173
그렇다면 여기서 드는 의문이 있다.
큰 단위의 바이트를 사용하면 모든 숫자나 문자 등을 표현할 수 있는데,
왜 굳이 프로그래밍을 하면 다양한 데이터 타입을 사용하는 것일까?
정답은 간단하다.
앞서 말했듯 컴퓨터는 받아들이는 모든 정보를 메모리에 저장하게 되는데,
예를 들어 1과 같은 작은 수를 표현하는데 4Byte를 사용해서 표현하게 되면,
그만큼의 메모리가 낭비되는 것이다.
이처럼 메모리가 넉넉하지 못한 환경에서 동작하는 프로그램을 사용한다면,
효율적으로 메모리를 사용하는 것이 중요하다는 것이다.
'IT 일반, 컴퓨터' 카테고리의 다른 글
| [네트워크] OSI 7계층 (네트워크 7계층) 이란? 계층별 특징 (0) | 2024.04.26 |
|---|---|
| [컴퓨터기초] 플래시 메모리(Flash Memory)에 대해서... (0) | 2024.04.21 |
| [컴퓨터 구조] ELF 파일 포맷 및 구성요소에 대해 알아보자 (1) | 2024.04.06 |
| [컴퓨터 구조] Interrupt (인터럽트)란? (0) | 2024.04.02 |
| [컴퓨터 구조] 컴퓨터 구조를 알아야 하는 이유 (0) | 2024.04.01 |



